TL;DR ///host.com is parsed as relative-path URL by server side libraries, but Chrome and Firefox violate RFC and load http://host.com instead, creating open-redirect vulnerability for library-based URL validations. This is WontFix, so don't forget to fix your code.
Think as developer.
Say, you need to implement /login?next_url=/messages functionality. Some action must verify that the next URL is either relative or absolute but located on the same domain.
What will you do? Let’s assume you will start with the easiest option - quick regexps and first-letters checks.
1. URL starts with /
Bypass: //host.com
2. URL starts with / but can’t start with //
Bypass: /\host.com
3. At this point you realize your efforts were lame and unprofessional. You will use URL parsing library, following all the RFC-s and such - \ is not allowed char in URL, all libraries wouldn't accept it. Much RFC, very standard.
require ‘uri’
uri = URI.parse params[:next]
redirect params[:next] unless uri.host or uri.scheme
Absence of host and scheme clearly says it is a relative URL, doesn’t it?
Bypass for ruby, python, node.js, php, perl: ///host.com
1 is for path, 2 is for host, 3 is for ?
https://dvcs.w3.org/hg/url/raw-file/tip/Overview.html#urls
>A scheme-relative URL is "//", optionally followed by userinfo and "@", followed by a host, optionally followed by ":" and a port, optionally followed by either an absolute-path-relative URL or a "?" and a query.
>A path-relative URL is zero or more path segments separated from each other by a "/", optionally followed by a "?" and a query.
A path segment is zero or more URL units, excluding "/" and "?".
Given we have base location as https://y.com and where will following URLs redirect?
/host.com is a path-relative URL and will obviously load https://y.com/host.com
//host.com is a scheme-relative URL and will use the same scheme, https, hence load https://host.com
The question is where ///host.com (also ////host.com etc) will redirect?
Out of question, it is a path-relative URL too. Third letter is /, so it can’t be a scheme-relative URL (which is only //, followed by host which doesn’t contain slashes).
It has 2 URL units which are empty strings, concatenated with / and supposed to load https://y.com///host.com
The thing is, both Chrome and Firefox parse it as a scheme-relative URL and load https://host.com Safari parses it as a path. Opera loads http://///x.com (?!).
http://www.sakurity.com/triple?to=///host.com#secret
where #secret can be access_token or auth code
Use a Library, Luke
Functionality like /login?to=/notifications is very common so can be found almost on any website. Now the question is how Good Programmers validate it?
As proved in the beginning of the post, best practise would be to use URL parser.
Let’s see how major platforms deal with ?next=///host.com
Perl (parses as a path)
use URI;
print URI->new("///x.com")->path;
Python (parses as a path)
import urllib
>>> urlparse.urlparse('//ya.ru')
ParseResult(scheme='', netloc='ya.ru', path='', params='', query='', fragment='')
>>> urlparse.urlparse('///ya.ru')
ParseResult(scheme='', netloc='', path='/ya.ru', params='', query='', fragment='')
>>> urlparse.urlparse('//////ya.ru')
ParseResult(scheme='', netloc='', path='////ya.ru', params='', query='', fragment='')
Ruby (parses as a path)
1.9.3-p194 :004 > URI.parse('///google.com').path
=> "/google.com"
1.9.3-p194 :005 > URI.parse('///google.com').host
=> nil
Node.js (parses as a path)
> url.parse('//x.com').host
undefined
> url.parse('///x.com').host
undefined
> url.parse('///x.com').path
'///x.com'
PHP (mad behavior, quite expected)
print_r( parse_url("///host.com"));
This doesn’t work (but should). You might be happy but wait, while all languages don’t parse /\host.com because it is not valid PHP gladly parses it as a path.
print_r( parse_url("/\host.com"));
Thus PHP is vulnerable too.
Security implications
Basically, with /\host.com and ///host.com we can get an open redirect for almost any website. Yeah. No matter you have “home made” parser or reliable server-side library - most likely it's vulnerable.
The only good protection is to respond with full path:
Location: http://myhost/ + params[:next]
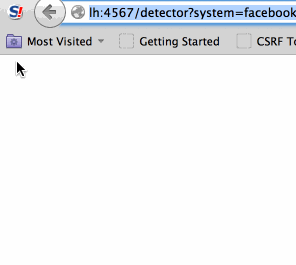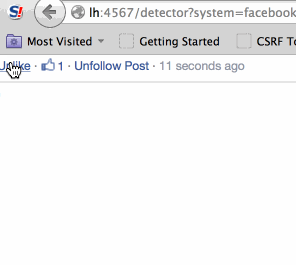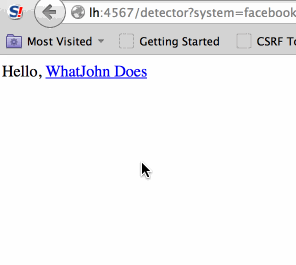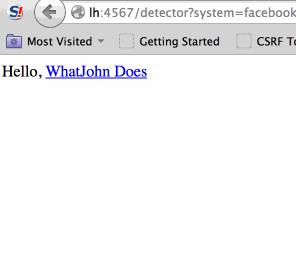
Besides phishing, redirects can exploit many Single Sign On and OAuth solutions: 302 redirect leaks #access_token fragment, and even leads to
total account takeover on websites with Facebook Connect (details soon).
























{kind=link}